琐碎点汇总

在 Node 环境中使用 ESM
两种方式:
- 把模块文件的后缀改成
.mjs; - 给最近的上级 package.json 文件添加名为
type的字段,并将字段值改成module。
ESM 中不支持 CommonJS 模块提供的某些引用
这包括:
- require
- exports
- module.exports
- __filename
- __dirname
要使用 require 函数,可以这样做:
import { createRequire } from 'module';
const require = createRequire(import.meta.url);
// 就可以使用 require 函数引用 CommonJS 模块了
import.meta.url可以获得当前模块的文件路径(文件网址字符串)。
要访问到 __filename 和 __pathname,可以这么做:
import { fileURLToPath } from 'url';
import { dirname, resolve } from 'path';
// 将文件网址转成路径地址
const __filename = fileURLToPath(import.meta.url);
const __dirname = dirname(__filename);
// 或者 const __dirname = resolve();
需要注意的是,ESM 的全局作用域中,
this是未定义的(undefined),而 CommonJS 中 this 则是指向exports的引用。
ESM 符号绑定
有两个文件,代码如下:
// b.mjs
export let count = 1;
export const increase = () => ++ count;
// a.mjs
import { count, increase } from './b.mjs';
console.log(count); // 1
increase();
console.log(count); // ?
运行后我们发现下面的 count 值变成了 2。ES Module 中导入的变量和导出的变量它们公用同一处内存空间,这与 JS 变量中的值类型和引用类型不同,被称为符号绑定(相当于 C/C++ 中的引用传递)。
在使用 import 进行导入时,这些绑定值只能被导入模块所读取(可读不可改),因此在 a.mjs 中修改 count 会报错。
编码顺序和字典顺序
比如有一些中文名字,我们希望按照拼音升序的方式进行排序,怎么正确的处理?
如果使用数组中自带的 sort API,你会发现排序并不准确,原因是 sort 默认排序是将元素转换为字符串,然后按照它们的 UTF-16 码元值升序排序。
假如要对 ['张三', '王五'] 数组按照拼音升序排列,预期应该是 ['王五', '张三'],但使用 sort 排序后发现不符合预期,原因是‘王’的码元值比‘张’的要大,所以排在了前面。
'张'.charCodeAt(); // 24352
'王'.charCodeAt(); // 29579
不过浏览器中为我们提供了另一个 API —— localeCompare,表示参考字符串在排序顺序中是在给定字符串之前、之后还是与之相同。如果引用字符串(referenceStr)存在于比较字符串(compareString)之前则为负数;如果引用字符串存在于比较字符串之后则为正数;相等的时候返回 0。比如:
'王'.localeCompare('张'); // -1,‘王’ 在 ‘张’ 之前
'w'.localeCompare('h'); // 1,‘w’ 在 ‘h’ 之后
'100'.localeCompare('20'); // -1,1 在 2 之前
因此字典排序就可以写成:
// < 0,a 在 b 前,[a, b](升序排列)
['张三', '王五'].sort((a, b) => a.localeCompare(b));
零宽字符
在开发中你是否遇到过这种问题,明明看着一模一样的字符串,结果对比的时候发现是 false,排查了半天也没有头绪。比如下面代码:
const str_1 = '零宽字符';
const str_2 = '零宽字符';
console.log(str_1 === str_2); // false 😭
console.log(str_1.length === str_2.length); // false 🤔
这是因为某个变量里存在零宽字符,比如 '零宽\u200d字符',当在��浏览器控制台输入时,得到的还是 “零宽字符” 字符串,\u200d 就是一个零宽字符(使用 vim 编辑器打开可以显示出来)。
在真实的场景下,用户可能复制了带有零宽字符的文本粘贴到了某个富文本或者表单中,导致我们代码中比较字符串时出现问题。
零宽字符在界面上没有任何宽度,也被叫做“幽灵字符”,下面的 Unicode 编码的字符都是零宽字符:
U+200B: 零宽度空格符,用于较长单词的换行分割;U+FEFF: 零宽度非断空格符,用于阻止特定位置的换行分割;U+200D: 零宽度连字符,用于阿拉伯与印度语系等文字中,使不会发生连字的字符间产生连字效应;U+200C: 零宽度段字符,用于阿拉伯文、德文、印度语系等文字中,阻止会发生连子的字符间的连字效果;U+200E: 左至右符,用于在混合文字方向的多种语音文本中(例如:混合左至右书写的英文与右至左书写的希伯来语),规定排版文字书写方向为左支右;U+200F: 右至左符,用于在混合文字方向的多种语言文本中,规定排版文字书写方向为右至左;
零宽字符可以用于数字水印,比如版权问题,防止别人复制粘贴,就可以在文本中插入零宽字符。
闭包漏洞
如何在不改变上面代码的情况下,修改 obj 对象?
const o = (function () {
const obj = {
a: 1,
b: 2,
};
return {
get: function(k) {
return obj[k];
}
};
})();
可能你会想到调用 valueOf(Object 原型上的方法)获取到原始的 obj 对象:
o.get('valueOf')();
但遗憾的是执行上面代码会报错,原因是 valueOf 方法内部使用了 this,但是上面的调用方式会丢失 this。
不过还是可以利用 Object.prototype 解决这个问题的,代码如下:
// 在 Object 原型对象上注册一个属性,getter 返回 this
Object.defineProperty(Object.prototype, 'abc', {
get: function() {
return this;
}
});
const obj = o.get('abc');
obj.a = '1111'; // 更改对象的属性值
console.log(o.get('a')); // '1111'
如何避免这种漏洞?
- ��是在
get中判断是不是 obj 自己的属性,是的话才去返回对应的属性值:
const o = (function () {
const obj = {
a: 1,
b: 2,
};
return {
get: function(k) {
if (obj.hasOwnProperty(k)) {
return obj[k];
}
return void 0;
}
};
})();
- 把 obj 对象的原型设置成 null
Object.setPrototypeOf(obj, null);
函数的二义性
fn(){} 是 js 中的一个函数,它既可以作为普通函数的方式调用(fn()),也可以使用构造函数的方式调用(new fn()),这种现象称为函数的二义性。
如果我们不想让 fn 函数作为构造函数调用(强行),怎么才能实现?
如果你运行的环境可以使用 ES6 API,则可以使用 new.target 检测函数或构造方法是否是通过 new 运算符被调用的。
new.target 返回一个指向构造方法或函数的引用。在普通的函数调用中,new.target 的值是 undefined。
function Foo() {
if (!new.target) throw "Foo() must be called with new";
console.log("Foo instantiated with new");
}
Foo(); // throws "Foo() must be called with new"
new Foo(); // logs "Foo instantiated with new"
在 ES6 的 class constructor 函数内部也可以访问 new.target。
EventSource API
一个 EventSource 实例会对 HTTP 服务器开启一个持久化的连接,以 text/event-stream 格式发送事件,此连接会一直保持开启直到通过调用 EventSource.close() 关闭。
EventSource 有固定的格式,下面代码是一个简单的 Node.js EventSource 后端代码:
import { URL } from 'node:url';
import { basename, resolve } from 'node:path';
import { createReadStream, statSync } from 'node:fs';
import { spawn, ChildProcessWithoutNullStreams } from 'node:child_process';
import { createServer, ServerResponse, IncomingMessage } from 'node:http';
const PORT = 8848;
const staticPath = resolve(__dirname, 'static');
function handleCpsErrors(cps: ChildProcessWithoutNullStreams, req: IncomingMessage, res: ServerResponse) {
cps.on('error', (error) => {
console.error('Ping command error:', error);
res.statusCode = 500;
res.end('Internal Server Error');
});
req.on('close', () => {
cps.kill(); // 客户端连接关闭时,杀死 ping 命令子进程
});
};
const http = createServer((req, res) => {
// 取出查询参数
const url = new URL(req.url, `http://localhost:${PORT}`);
const query = url.searchParams;
const method = (req.method || 'GET').toUpperCase();
const { pathname } = url;
if (pathname === '/ping' && method === 'GET') {
const pingHost = query.get('host');
const pingCount = query.get('count') || '4';
const pingSpawn = spawn('ping', [pingHost, '-c', pingCount]);
handleCpsErrors(pingSpawn, req, res);
// 设置响应标头
res.setHeader('Content-Type', 'text/event-stream');
res.statusCode = 200;
pingSpawn.stdout.setEncoding('utf-8');
res.write('event: message\n');
pingSpawn.stdout
.on('data', (data: string) => {
const dataBlocks = data.split('\n');
dataBlocks.forEach((block) => {
res.write(`data: ${block}\n\n`);
});
}).on('end', () => {
res.end(`data: [DONE]\n\n`);
});
}
});
http.listen(PORT, () => {
console.log(`Server listening on http://localhost:${PORT}`);
});
EventSource 有固定的消息格式:event: message\n 和 data: xxx\n\n,前者代表在前端监听消息的时间,这里使用 message 作为事件名称;而后者就代表发送的数据,需要注意是,每条数据需要使用 \n\n 换行符分割(约定的格式)。在前端我们就可以请求 /ping,监听 message 事件获取 data 了!
const source = new EventSource(`/ping?host=${host}&count=6`);
// 如果后端不是使用的 `event: message`,
// 而是使用了 `event: msg`,你需要使用
// `source.addEventListener('msg', (event) => { ... })` 来监听事件
source.onmessage = (event) => {
if (event.data === '[DONE]') {
return source.close();
}
element.textContent += `${event.data}\n`;
}
分块加载
Response.body.getReader() API 可以让我们能够分块获取数据。上面的 EventSource API 也可以使用 getReader() 来实现:
// default 'utf-8' or 'utf8'
const utf8decoder = new TextDecoder();
const receivePingMsg = async (host) => {
view.textContent = '';
try {
const response = await fetch(`/ping?host=${host}&count=6`, {
method: 'GET'
});
const reader = await response.body.getReader();
let result = await reader.read();
while(!result.done) {
const text = utf8decoder.decode(result.value);
view.textContent += text;
result = await reader.read();
}
} catch (error) {
console.log("error:", error);
}
}
需要注意的是,因为
reader.read()的 value 是 Uint8Array,后台和前端应该约定好编码格式,不然很可能出现乱码的情况。比如在传输文本是,双方可以约定使用 utf-8 的编码。
HTMLCollection 与 NodeList
假如有一个按钮,当点击这个按钮时,就会把 li 全部 copy 一份追加到 ul 中,代码如下:
<body>
<ul>
<li class="item">q-w-e-r-t-y-u-i-o-p</li>
<li class="item">a-s-s-s-d-f-g-h-j-k-l</li>
<li class="item">z-x-c-v-b-n-m</li>
<li class="item">1-2-3-4-5-6-7-8-9-0</li>
</ul>
<button>copy list</button>
<script>
const button = document.getElementsByTagName('button')[0];
const list = document.getElementsByTagName('ul')[0];
const items = document.getElementsByClassName("item");
button.addEventListener("click", () => {
for (let i = 0; i < items.length; i++) {
// 深度克隆节点
const clonedElm = items[i].cloneNode(true);
list.appendChild(clonedElm);
}
});
</script>
</body>
运行代码会发现页面卡死了,原因是 getElementsByClassName API 返回的是一个 HTMLCollection 对象,原因是这个对象是即时更新的(live);当其所包含的文档结构发生改变时,它会自动更新。因此,最好是创建副本(例如,使用 Array.from)后再迭代这个数组以添加、移动或删除 DOM 节点。
当我们 appendChild(clonedElm) 后,url 中的 li 元素长度就改变了,下次 for 循环再读长度就发现长度变了,就会一直循环下去。
解决办法是创建副本,或者使用 querySelectorAll API,这个 API 返回的是 NodeList 对象,在一些情况下,NodeList 是一个实时集合,也就是说,如果文档中的节点树发生变化,NodeList 也会随之变化。例如,Node.childNodes 是实时的;
在其他情况下,NodeList 是一个静态集合,也就意味着随后对文档对象模型的任何改动都不会影响集合的内容。比如 document.querySelectorAll 就会返回一个静态 NodeList。
// 静态集合,非计时更新
const items = document.querySelectorAll(".item");
无法取消的默认行为
假如有这样一个场景,页面内容比较多,存在滚动条,里面还用到了弹窗组件,我们期望当弹窗出现时,页面内容的滚动禁止,当弹窗关闭后,页面内容再次可以滚动。代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<style>
body, html {
margin: 0;
padding: 0;
}
.container {
height: 140vh;
}
.modal {
position: fixed;
top: 0;
height: 100vh;
width: 100vw;
display: none;
}
.mask {
position: absolute;
top: 0;
left: 0;
bottom: 0;
right: 0;
background-color: rgba(0, 0, 0, 0.2);
}
.close-btn {
position: absolute;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
z-index: 2;
}
</style>
</head>
<body>
<button class="open">弹窗</button>
<div class="container">内容区域</div>
<div class="modal">
<div class="mask"></div>
<button class="close-btn">关闭</button>
</div>
<script>
const $ = document.querySelector.bind(document);
const modal = $('.modal');
const button = $('.open');
const closeBtn = $('.close-btn');
const preventWheelEventDefault = (e) => {
e.preventDefault();
}
button.addEventListener('click', () => {
modal.style.display = 'block';
// 阻止页面滚动行为
window.addEventListener('wheel', preventWheelEventDefault);
}, false);
closeBtn.addEventListener('click', () => {
modal.style.display = 'none';
// 移除事件
window.removeEventListener('wheel', preventWheelEventDefault);
}, false);
</script>
</body>
</html>
调试时结果发现控制台报错了:
[Intervention] Unable to preventDefault inside passive event listener due to target being treated as passive. See [<URL>](https://www.chromestatus.com/feature/6662647093133312)
按照提示,我们把 wheel 事件的 addEventListener 第三个参数改成下面代码后就不报错了,页面也不会滚动了。
window.addEventListener('wheel', preventWheelEventDefault, {
passive: false
});
passive: false 的具体作用是什么呢?
它的默认值时 true,表示 listener 永远不会调用 preventDefault()。如果 listener 仍然调用了这个函数,客户端将会忽略它并抛出一个控制台警告。值是 true 时,浏览器会启用性能优化,并可大幅改善应用性能。
根据规范,addEventListener() 的 passive 默认值始终为 false。然而,这引入了触摸事件和滚轮事件的事件监听器在浏览器尝试滚动页面时阻塞浏览器主线程的可能性——这可能会大大降低浏览器处理页面滚动时的性能。
为了避免这一问题,大部分浏览器(Safari 和 Internet Explorer 除外)将文档级节点 Window、Document 和 Document.body 上的 wheel、mousewheel、touchstart 和 touchmove 事件的 passive 默认值更改为 true。如此,事件监听器便不能取消事件(阻止默认行为可能会影响到浏览器对这些事件的优化),也不会在用户滚动页面时阻止页面呈现。
JS 标记语句
下面代码,如何跳出外层的 for 循环?
for (var i = 0; i < 3; i++) {
for (var j = 0; j < 3; j++) {
console.log('j ====> ', j);
break;
}
console.log('i ====> ', i);
}
标记语句可以和 break 或 continue 语句一起使用。标记就是在一条语句前面加个可以引用的标识符。
上面代码如果要跳出外层的 for 循环,可以这样做:
outerLoop: for (var i = 0; i < 3; i++) {
for (var j = 0; j < 3; j++) {
console.log('j ====> ', j);
break outerLoop;
}
console.log('i ====> ', i);
}
需要注意的是,JavaScript 没有
goto语句,标记只能和 break 或 continue 一起使用。
使用 void 0 替代 undefined
为什么很多库或者代码规范中要用 void 0 替代 undefined?
原因是 undefined 比较“奇葩”:
undefined 不是关键字(是 window 对象中的一个只读属性),因此你可以使用 undefined 去声明一个变量;
'undefined' in window // true
console.log('window undefined:', undefined); // undefined
function fn() {
let undefined = 111;
console.log('function undefined:', undefined); // 111
}
在非全局环境我们是可以声明并修改 undefined 这个变量的,因此显示使用 undefined 可能会存在隐患(不再是值,而是一个变量),使用 void 0 运算就可以一直获取到 undefined 这个值。
DataTransfer
拖拽简单实现:
- 在
dragstart事件处理器中,我们获得对用户拖动的元素的引用。 - 在目标容器的
dragover事件处理器中,我们调用event.preventDefault(),以使得该元素能够接收drop事件。 - 在放置区域的
drop事件处理器中,我们将可拖动元素从原先的容器移动到该放置区域。
拖拽的时候可以给 drop 元素传递数据:
const dragElm = document.querySelector('.drag');
const dropElm = document.querySelector('.drop');
dragElm.addEventListener('dragstart', (e) => {
// 设置数据
e.dataTransfer.setData('data', 'hello~');
}, false);
dropElm.addEventListener('dragover', (e) => {
e.preventDefault();
}, false);
dropElm.addEventListener('drop', (e) => {
// 获取数据
const dragData = e.dataTransfer.getData('data');
console.log("🚀 ~ file: data-transfer.html:40 ~ dropElm.addEventListener ~ dragData:", dragData);
}, false);
当我们在处理拖拽交互时,不用把数据存到某个 store 里,drop 的时候再读取,这样反而会出现问题,比如 drag 的时候松开了,并没有 drop 到目标元素上,但数据已经保存了。假如用户在别的地方(别的app、或者页面中的图片和复制的文本)拖拽东西到目标元素也会获取 store 数据的问题。
参考
渲染主线程与合成线程
下面代码有两个小球,分别对他们设置了动画,ball-1 使用 transform,而 ball-2 使用 left。当点击按钮时会进入 5s 的死循环,大家觉得这两个小球还不会不会继续运动?
<html lang="en">
<head>
<style>
* {
margin: 0;
padding: 0;
}
.ball {
width: 120px;
height: 120px;
margin-top: 100px;
border-radius: 50%;
}
.ball-1 {
background-color: skyblue;
animation: move-1 2s linear 0s infinite alternate;
}
@keyframes move-1 {
to {
transform: translateX(400px);
}
}
.ball-2 {
background-color: blueviolet;
position: absolute;
left: 0;
top: 300px;
animation: move-2 2s linear 0s infinite alternate;
}
@keyframes move-2 {
to {
left: 400px;
}
}
button {
height: 32px;
line-height: 32px;
padding: 0 24px;
border: none;
cursor: pointer;
margin: 20px;
font-size: 18px;
color: brown;
}
</style>
</head>
<body>
<button>delay</button>
<div class="ball ball-1"></div>
<div class="ball ball-2"></div>
<script>
const btn = document.querySelector('button');
const delay = (time) => {
const datumLine = Date.now();
while(Date.now() - datumLine < time);
}
btn.addEventListener('click', () => {
delay(5000); // 5s 延迟
});
</script>
</body>
</html>
渲染原理
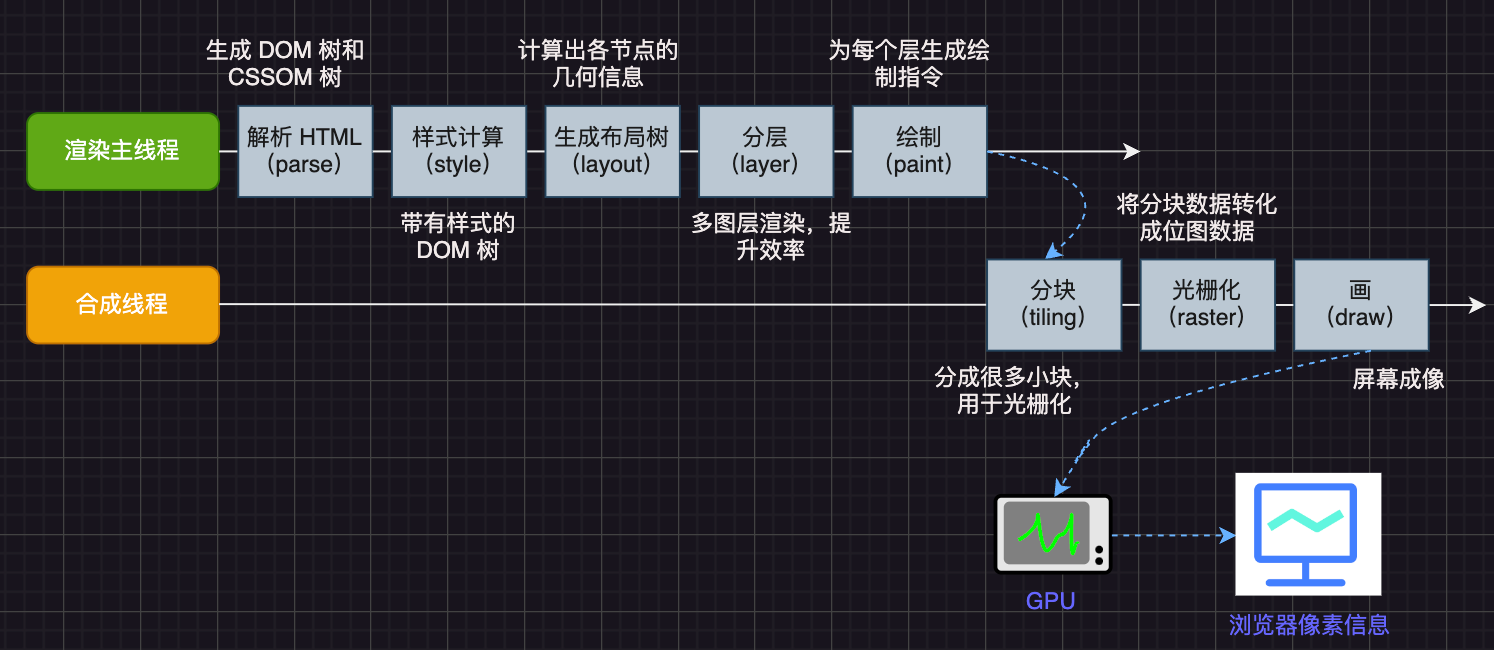
渲染进程启动后,会开启一个渲染主线程,主线程负责执行 HTML、CSS、JS 代码。
默认情况下,浏览器会为每个标签页开启一个新的渲染进程,以保证不同的标签页之间互不影响。
当我们更改 ball-2 的 left 属性值时,会引起 reflow(重排),主线程会重新计算样式(style 阶段)导致后续一系列的渲染流程,但这时候任务队列中正在运行 delay 函数,渲染的任务还无法执行,ball-2 的小球就不动了。
在执行 js 代码时,ball-1 却还在运动,这是因为变形发生在合成线程,与渲染主线程无关,transform 的变化几乎不会影响渲染主线程,这就是 transform 效率高的本质原因。
除了 transform 外,浏览器中的默认的滚动条也是不受影响的,它也不在渲染主线程上。
包含块
- 元素的 width 百分比相对的是包含块的宽度;
- 元素的 height 百分比相对的是包含块的高度;
- 元素的 margin 百分比相对的是包含块的宽度;
- 元素的 padding 百分比相对的是包含块的宽度;
- 元素的 left 相对的是包含块的左边缘;
- 元素的 top 相对的是包含块的上边缘;
确定一个元素的包含块的过程完全依赖于这个元素的 position 属性:
-
如果 position 属性为 static、relative 或 sticky,包含块可能由它的最近的祖先块元素(比如说 inline-block, block 或 list-item 元素)的内容区的边缘组成(content 区域,不包含 padding),也可能会建立格式化上下文 (比如说 a table container, flex container, grid container, 或者是 the block container 自身)。
-
如果
position属性为absolute,包含块就是由它的最近的 position 的值不是 static (也就是值为fixed, absolute, relative 或 sticky)的祖先元素的内边距区的边缘(包含 pading 区域)组成。 -
如果 position 属性是
absolute或fixed,包含块也可能是由满足以下条件的最近父级元素的内边距区的边缘组成的:- transform 或 perspective 的值不是 none;
- will-change 的值是 transform 或 perspective;
- filter 的值不是 none 或 will-change 的值是 filter(只在 Firefox 下生效);
- contain 的值是 paint(例如:contain: paint;);
- backdrop-filter 的值不是 none(例如:backdrop-filter: blur(10px);)
参考:MDN: 布局和包含块
CSS backdrop-filter
backdrop-filter CSS 属性可以让你为一个元素后面区域添加图形效果(如模糊或颜色偏移)。因为它适用于元素背后的所有元素,为了看到效果,必须使元素或其背景至少部分透明。
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>backdrop-filter</title>
<style>
body {
margin: 0;
padding: 0;
height: 100vh;
}
.box {
height: 50%;
position: relative;
}
.mask {
width: 100%;
height: 100%;
position: absolute;
backdrop-filter: grayscale(1);
transition: all 4s linear;
}
.box:hover .mask {
width: 2px;
right: 0;
}
.img {
background-image: url(./01.jpg);
height: 100%;
width: 100%;
background-size: cover;
}
</style>
</head>
<body>
<div class="box">
<div class="mask"></div>
<div class="img"></div>
</div>
</body>
毛玻璃效果

<style>
body {
height: 100vh;
width: 100vw;
margin: 0;
padding: 0;
background-image: url(./01.jpg);
background-repeat: no-repeat;
background-size: cover;
overflow: hidden;
}
div {
margin: 200px auto;
padding: 60px;
border-radius: 6px;
width: fit-content;
background-color: rgba(255, 255, 255, 0.2);
backdrop-filter: blur(2px);
color: white;
font-size: 32px;
}
</style>
<body><div></div></body>
CSS 混合模式
<blend-mode> 是一种 CSS 数据类型,用于描述当元素重叠时,颜色应当如何呈现。它被用于 background-blend-mode 和 mix-blend-mode 属性。
比如下面效果,就可以很容易的使用 css blend-mode 实现。
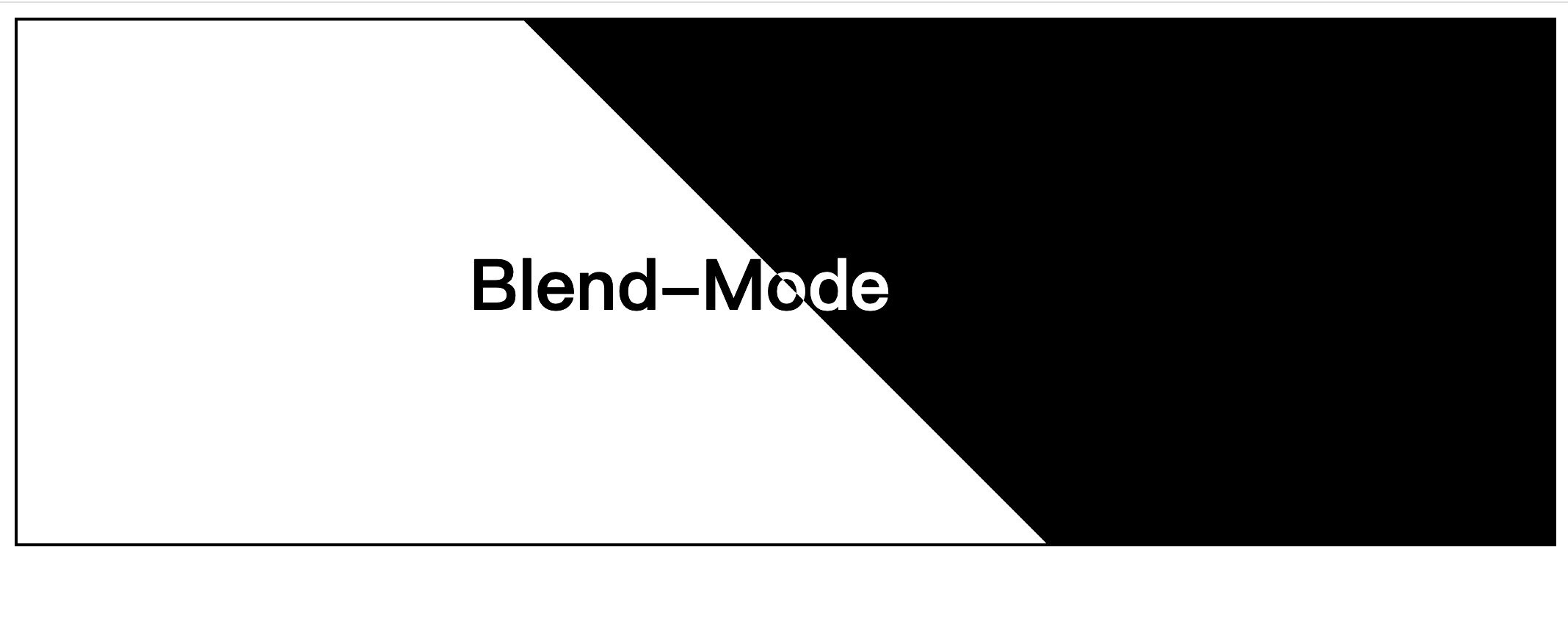
代码如下:
<html lang="en">
<head>
<style>
html, body {
margin: 0;
padding: 0;
}
.container {
margin: 10px;
position: relative;
height: 360px;
border: 2px solid black;
box-sizing: border-box;
background-image: linear-gradient(45deg, white 0 50%, black 50% 100%);
background-size: 100% 100%;
background-repeat: no-repeat;
}
.container:hover h2 {
transform: translateX(36px);
}
h2 {
text-align: center;
font-size: 48px;
height: 100%;
color: white;
line-height: 360px;
mix-blend-mode: difference;
padding: 0;
margin: 0;
transform: translateX(-72px);
transition: transform 1s;
}
</style>
</head>
<body>
<div class="container">
<h2>Blend-Mode</h2>
</div>
</body>
</html>
mix-blend-mode CSS 属性描述了元素的内容应该与元素的直系父元素的内容和元素的背景如何混合。difference 表示会反转颜色,但黑色层不会造成变化,而白色层会反转另一层的颜色,比如父元素背景是白色,子元素会反转成黑色。
flex + margin
让一个元素居中可以这样实现:
.parent {
display: flex;
align-items: center;
justify-content: center;
}
除了这种方式之外,还可以设置子元素的 margin 样式实现:
<style>
.box {
display: flex;
}
.box-1 {
height: 360px;
border: 1px solid black;
}
.item {
width: 40px;
height: 40px;
background-color: red;
/** 自动占用上下左右的空间 */
margin: auto;
}
</style>
<div class="box box-1">
<div class="item"></div>
</div>
除此之外,margin 属性和 flex 配合可以很方便的实现一些布局。
<style>
.box-2 .item:last-of-type {
/* 把左边的剩余空间占用掉 */
margin-left: auto;
}
</style>
<div class="box box-2">
<div class="item"></div>
<div class="item"></div>
</div>
效果与 space-between 一致。

<style>
.box-5 .item:nth-of-type(3) {
/* 左右各占用一般的空间 */
margin: 0 auto;
}
</style>
<div class="box box-5">
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
</div>

甚至还可以通过计算,把元素等距排列:
<style>
.box-6 {
flex-wrap: wrap;
--n: 10;
--gap: calc((100% - 40px * var(--n)) / var(--n) / 2);
}
.box-6 .item {
width: 40px;
height: 40px;
margin: 16px var(--gap);
}
</style>
<div class="box box-6">
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
</div>

box-shadow 与 drop-shadow
当我们想给一个带有透明度的图片设置阴影时,结果出现了这种效果,并不符合我们的预期。

这是因为 box-shadow 属性用于在元素的框架上添加阴影效果,而我们只想针对图片中的像素设置阴影,这时候我们就可以使用 filter: drop-shadow 来实现,它会创建一个符合图像本身形状 (alpha 通道) 的阴影。
img {
filter: drop-shadow(0 0 6px rgba(0, 0, 0, 0.8));
}
transform 多重变换
给 css transform 属性应用多个变化函数时,复合变换是按从右到左的顺序有效地应用。
比如下面例子,给 div 元素设置了两个变换:
div {
width: 200px;
height: 200px;
background-color: greenyellow;
transform: rotate(120deg) translate(200px, 200px);
}
运行后发现 div 元素不见了。原因是先执行了 translate 变换,默认情况下变换的原点处在元素的中心位置(这可以通过 transform-origin 来设置),然后再执行 rotate,而元素的 transform-origin 对应的点是在原来未变换前的中心位置,以这个位置进行旋转 120deg 就会把元素旋转到左侧看不到的位置。

保持元素宽高比
场景:随着视口的变化,元素的宽度和高度比值相等,例如视频网站的视频区域,可以使用 aspect-ratio 很方便的实现。
div {
width: 75vw;
background-color: skyblue;
/** width / height 为 4:3 */
aspect-ratio: 4/3;
margin: 100px auto;
}
CSS @property
@property 是 CSS Houdini API 的一部分,它允许开发者显式地定义他们的 CSS 自定义属性, 允许进行属性类型检查、设定默认值以及定义该自定义属性是否可以被继承。
比如下面一个例子,在没有 Houdini API 之前,我们使用 CSS animation 是无法更改 css 渐变的。
div {
height: 240px;
background-image: linear-gradient(to right,rgba(0, 0, 255, 0.5), rgba(255, 255, 0, 0.5));
animation: colorChange 1s linear infinite alternate;
}
@keyframes colorChange {
to {
background-image: linear-gradient(to right,rgba(255, 0, 255, 0.5), rgba(0, 255, 0, 0.5));
}
}
使用 Houdini API 就可以解决这个问题:
@property --gradient {
syntax: "<color>";
inherits: false;
initial-value: #c0ffee;
}
div {
height: 240px;
--gradient: rgba(0, 0, 255, 0.5);
background-image: linear-gradient(to right,var(--gradient), rgba(255, 255, 0, 0.5));
animation: colorChange 1s linear infinite alternate;
}
@keyframes colorChange {
to {
--gradient: rgba(255, 0, 255, 0.5);
}
}
其他
-
给元素设置为
fixed定位后,当元素祖先的 transform、perspective、filter 或 backdrop-filter 属性非 none 时,容器由视口改为该祖先。参考 -
scroll-behavior 属性值为
smooth时可以让我们的元素对应的滚动效果更佳丝滑。 -
当你的浏览器切换到别的标签页时,浏览器为了提升效率,为了减少电量消耗,它就会不那么频繁的去执行计时器了,chrome 浏览器会把计时器的时间间隔调整成最少1s(不同浏览器可能不一致),因此所有小于 1s 的定时器都会被重置为1s或者别的重置值。当你使用定时器实现动画时,可以监听
visibilitychange事件,把动画暂停,切回 tab 页时再继续或者重置。 -
Element 接口的 scrollIntoView() 方法会滚动元素的父容器,使被调用 scrollIntoView() 的元素对用户可见,还支持传入
behavior进行平滑滚动。场景:列表右侧拼音导航,手指点击某个字母时跳到对应的列表。 -
圈复杂度 是衡量代码质量的一个重要标准,它有一套计算方式,算出来的是一个数值,这个数值越大,表示你的代码复杂度越高,代码也就越不容易�维护,越不好进行测试,反之代码质量就越高(一般这个数值控制在 10-20之间)。在
eslint中就可以配置圈复杂度,它可以自动帮我们计算出圈复杂度。{
rules: {
// 圈复杂度为 15 时代码就会报错
complexity: ["error", 15]
}
} -
如果正则表达式设置了全局标志,
RegExp.test()的执行会改变正则表达式lastIndex属性。连续的执行test()方法,后续的执行将会从lastIndex处开始匹配字符串,(exec()同样改变正则本身的lastIndex属性值)。 -
canvas.height = 40 的这种赋值是代表 canvas 的原始尺寸,为 canvas 元素设置 css 样式的 height/width 是设置的样式尺寸,两者的关系为:
原始尺寸 = 样式尺寸 * 放大倍率,放大倍率可以用 window.devicePixelRatio 获取到,当缩放屏幕时,要想让 canvas 绘制的图片不模糊,可以使用 matchMedia() API监控设备分辨率并在每次更改时检查devicePixelRatio的值,重新计算出原始样式。 -
对于附带身份凭证的请求(比如 cookie),服务器不得设置 access-control-allow-origin 的值为
*,设置了还是会有跨域问题。 -
Access-Control-Expose-Header头让服务器把允许浏览器访问的头放入白名单。