README
CommonJS模块
模块加载过程
当我们在Node.js中调用require()引入某个模块时,模块的加载流程大致如下:

moduleName就是我们要引入的包名,在考虑文件模块与包模块的时候,文件与目录都有资格与moduleName相匹配,匹配规则为:
- 首先看有没有文件名是
moduleName且后缀是.js的文件; - 其次看有没有名为
moduleName的目录,并且该目录下有没有名为index.js的文件; - 最后看有没有名叫
moduleName的目录,并且该目录下有没有package.json文件,若有,则采用其中的main属性所指定的目录或文件。
CommonJS是首个内置于 Node.js 平台的模块系统。CommonJS 规范里的两个基本理念:
- 可以通过
require函数,引入本地文件系统之中的某个模块; - 可以通过
exports与module.exports这两个特殊变量,把想要公布给外界的功能,从当前模块中导出;
下面代码可以模拟Node.js本身的require函数中的一部分内容:
import fs from "node:fs";
function loadModule(filename, module, require) {
const wrappedSrc = `
(function (module, exports, require) {
${fs.readFileSync(filename, "utf8")}
})(module, module.exports, require)
`;
eval(wrappedSrc);
}
function require(moduleName) {
const id = require.resolve(moduleName);
if(require.cache[id]) {
return require.cache[id].exports;
}
// 模块的元数据
const module = {
exports: {},
id,
};
// 更新缓存
require.cache[id] = module;
// 加载模块
loadModule(id, module, require);
// 返回导出的变量
return module.exports;
}
require.cache = {};
require.resolve = (moduleName) => {
/** 根据 moduleName 解析出完整的模块 id */
};
上面代码中,我们写了loadModule和require两个函数,loadModule函数注意是用于读取模块内容并把代码包装到一个IIFE(立即执行函数表达式)中,并在使用eval执行模块。
而在require函数中,我们先调用resolve()函数获取id,然后先从缓存中取模块,如果能取到则直接返回module.exports中导出的内容。如果没有从缓存中找到,则构建一个模块的元数据,更新缓存,并加载模块,最后返回导出的变量。
由此可见,Node.js 模块系统并没有神秘的地方,我们只不过是把模块的源代码包裹了起来,并且手工创建了一套环境,将这些源代码放在这套环境里运行。
通过上面代码我们可以发现,loadModule中构建的wrappedSrc变量里,立即执行函数接收的形参module和exports分别来自于module和module.exports这两个实参,而require()函数最终返回的是module.exports变量。这意味着要想通过exports变量导出内容,我们只能想下面这样,给该变量安插新的属性:
exports.foo = () => {}
假如直接给exports变量赋值,那么不会有任何作用,因为这改变不了module.exports的内容。这只不过是让exports变量本身指向另外一份内容。下面这种写法是错误的:
exports = () => {}
require()是一个同步函数,所以针对module.exports的赋值操作,也必须是同步的,例如下面这种写法就不正确。
// a.js
setTimeout(() => {
module.exports = 'hello';
}, 100);
// b.js
const r = require('./a.js');
console.log(r); // 结果是一个空对象:{}
循环依赖
循环依赖这种问题有可能出现在实际的项目之中。举一个例子,有一个名叫main.js的模块,要依赖a.js和b.js这两个模块,其中a.js又依赖b.js。但问题是b.js反过来还依赖a.js,这就形成了循环依赖。
 代码如下:
代码如下:
// main.js
const a = require('./a');
const b = require('./b');
console.log('a => ', JSON.stringify(a, null, 2));
console.log('b => ', JSON.stringify(b, null, 2));
// a.js
exports.loaded = false;
const b = require('./b');
module.exports = { b, loaded: true };
// b.js
exports.loaded = false;
const a = require('./a');
module.exports = { a, loaded: true };
当运行main.js时,会看到下面的输出信息:
$ node ./main.js
a => {
"b": {
"a": {
"loaded": false
},
"loaded": true
},
"loaded": true
}
b => {
"a": {
"loaded": false
},
"loaded": true
}
在观察a.js和b.js模块所导出的内容时,可能看到不同的结果,具体会看到什么取决于相互依赖的这些模块究竟是按照什么顺序加载的。下面我们一步步分析这些模块是怎么加载进来的。
- 整个流程从
main.js开始,这个模块一开始就要求载入a.js模块; a.js首先是导出了一个名为loaded的变量,并且值是false;- 然后
a.js模块要求载入b.js模块; - 进入到
b.js中,它首先也是导出了一个名为loaded的变量,并且值设置为false; - 然后
b.js又反过来导入a.js模块(形成了循环依赖); - 由于系统已经开始处理
a.js模块了,因此b.js模块会把a.js目前已经导出的内容,立刻复制到本模块的范围内(a.js模块中一开始导出的loaded=false内容); - 最后
b.js模块把自己刚才导出的loaded值改为true; b.js执行完毕,控制权回到a.js这里,它会把b.js模块当前的状态拷贝一份,放到自己这里(此时b.js导出的 a 是loaded: false和自身的loaded: true);a.js模块执行最后一步,就是把刚才导出的loaded值改为true;a.js模块执行完毕,控制权回到main.js这里,它会把a.js模块当前的状态拷贝一份,放到自己这里(此时a.js中的b变量就是第八步中b.js导出的内容,还有自己的loaded: true);main.js要求载入b.js,由于该模块已经载入,因此系统立刻从缓存中返回该模块;main.js把b.js模块的当前状态拷贝一份,放到自己这里来,至此,我们就看到了每个模块的最终状态
如果我们无法控制哪个模块应该提前加载,那么这种循环依赖关系所产生的结果,就特别混乱,这对于大型项目来说,更加严重。
ECMAScript模块(ESM)
ESM模块语法相当简洁,它支持循环依赖,而且能够异步加载模块。
ESM与CommonJS的一项重要区别,在于ES模块是静态的,也就是说,引入这种模块的那些语句,必须写在最顶层,而且要置于控制流之外。
// 不能使用下面这种方式引入 ES 模块
if (condition) {
import module1 from 'module1';
} else {
import module2 from 'module2';
}
// CommonJS 模块则可以根据条件来引入
let module = null;
if (condition) {
module = require('module1');
} else {
module = require('module2');
}
Node.js 默认把所有.js的文件都当成采用CommonJS语法所写的文件。如果想在Node.js中使用ES模块,有这么几种办法:
- 把模块文件的后缀名写成
.mjs; - 在最近的
package.json文件添加名为type的字段,并将字段值设置为module;
需要注意的是,在Node.js中使用
ESM模块时,它要求�用户必须把要引入的那个模块所在的文件扩展名写出来,在CommonJS中则可以省略文件扩展名,而在ESM模块系统里不能省略最后的.js。
模块加载过程
解释器的目标是构建一张图,以描述所要载入的这些模块之间的依赖关系,这种图也被称为依赖图(dependency graph)。
解释器会从入口点(entry point)出发,寻找所有的import语句,如果在寻找过程中遇到了import语句,那就会以深度优先的方式递归,直到把所有的代码解析并执行完毕为止。具体这个过程可以细分成三个阶段:
- 构造(Construction)/解剖(Parsing):寻找所有的引入语句,并递归地从相关文件里加载每个模块地内容;
- 实例化(Instantiation):针对每个导出,在内存中保存一个带名称地引用,但暂且不给它赋值。另外,还要针对所有的
import语句和export语句创建引用,以记录它们之间地依赖关系(这叫做链接,linking),这一阶段不会执行任何JS代码; - 执行(Evaluation):在这一阶段,Node.js 可以从入口点开始,顺畅地往下执行代码,因为其中有待解析的那些地方,都已经全部解析清楚了。
简单来说,第一阶段就是找到依赖图中所有的点,第二阶段地任务是在有依赖关系的点之间创建路径,第三阶段则是按照正确的顺序遍历这些路径。
ESM模块解析与CommonJS与有着重大差异,由于CommonJS是动态的,它是一边解析依赖图,一边执行相关的文件。于是我们只要看到一条require语句,就可以断定,当程序来到这条语句时,它肯定已经把前面应该执行地代码全都执行完了,甚至可以出现在if语句或循环结构里。
而ESM系统则不同,在ESM中,三个阶段是彼此分离的,它必须先把依赖图完整地构建出来,然后才能开始执行代码。因为引入模块和导出模块都必须是静态的。
只读的 live 绑定
ES模块还有一项重要的特征:它在引入进来的模块与该模块所导出地值之间,建立了一种live绑定关系,然而这种绑定关系在引入方这一端是只能读而不能写的。
// counter.js
export let count = 0;
export function increment() {
count ++;
}
// main.js
import { count, increment } from './counter.js';
console.log(count); // 0
increment();
console.log(count); // 1
count ++; // TypeError: Assigment to constant variable!
通过上面代码我们可以看到,count变量地值随时都可以读取,并且可以由模块中increment()函数所修改,但是如果我们手动修改count,那就跟试图修改常量一样,会让程序出错。这意味着我们只能设法让引入的这个变量在原模块地范围内发生变化,而那个范围是使用这个模块的人无法控制的。
这跟CommonJS中所用的方法由根本区别,如果某个模块要引入的是CommonJS模块,那么系统就会对后者的整个exports对象做拷贝(这种拷贝是浅拷贝,shalow copy),从而将其中的内容复制到当前模块里,于是,数字或者字符串等原始类型的变量就会出现副本,而不会与原模块中的响应变量联动。这样的话,如果受引用的那个模块修改了自身的那一份变量,那么用户这边是看不到新值的。
解析循环依赖
还是以上面三个文件的引用关系为例,代码如下:
// main.mjs
import * as a from './a.mjs';
import * as b from './b.mjs';
console.log('a => ', a);
console.log('b => ', b);
// a.mjs
import * as bModule from './b.mjs';
export let loaded = false;
export const b = bModule;
loaded = true;
// b.mjs
import * as aModule from './a.mjs';
export let loaded = false;
export const a = aModule;
loaded = true;
在main.js中我们并没有使用JSON.stringify方法,那样会出现TypeError: Converting circular structure to JSON错误,因为a.js和b.js之间由循环引用关系。
运行结果如下:
 运行后我们发现,与
运行后我们发现,与CommonJS的运行结果不一样,a中的b与b中的a,其loaded值都是true。a里面的那个b跟当前范围中的b是同一个实例,b中的a跟当前范围中的这个a也是同一个实例。
下面我们分析一下模块的整体解析流程。
- 第一阶段:构造
- 从
main.mjs开始构造,首先发现一条import语句,这条语句把我们带到a.mjs中; - 从
a.mjs往下剖析,我们发现了一条import语句,这条语句把我们带到b.mjs中; - 从
b.mjs往下剖析��,我们发现了一条import语句,这条语句想要回过头引用a.mjs,但由于a.mjs刚才已经访问过了,因此我们不会沿着这条路径往回走; - 处理完这条
import语句之后,继续剖析b.mjs,由于其中已经没有别的import语句了,因此我们回到a.mjs,然而a.mjs中也没有了import语句,因此我们回到了main.mjs继续往下剖析,这次我们发现了import语句,它要引入b.mjs,由于这个模块刚才已经访问过了,因此我们不会沿着这条路往回走;
- 从
- 第二阶段:实例化,这一阶段解释器会从树状结构的底部开始,逐渐往顶部走,每走到一个模块,它就寻找该模块所要导出的全部属性,并在内存中构建一张映射表,以存放此模块所要导出的属性名称与该属性即将拥有的取值(这些值在这个阶段不做初始化)
- 解释器首先从
b.mjs模块开始,它发现这个模块要导出loaded与a; - 然后解释器又分析
a.mjs模块,它发现这个模块要导出loaded与b; - 最后,解释器分析
main.mjs模块,它发现这个模块不导出任何功能; - 最后解释器会把各个模块所导出的名称与引用这些名称的那些模块给链接起来;
- 解释器首先从
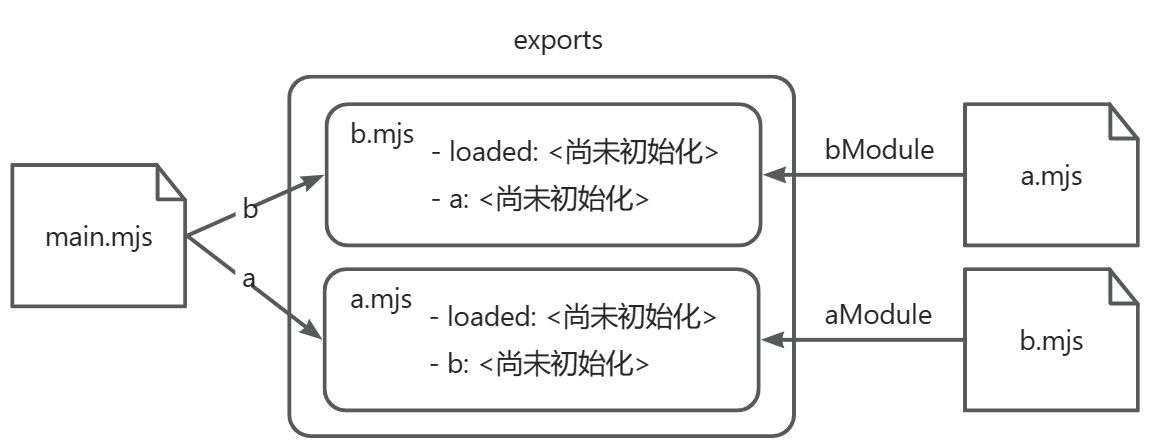
- 第三阶段:执行。它会按照后序的深度优先(post-order depth first)顺序,由下而上地访问最初那张依赖图,并逐个执行访问到的文件。
- �从
b.mjs开始执行。首先要把该模块所导出地loaded值初始化成false; - 接下来让该模块所所导出的
a属性得到初始值,这个值是一个指向模块对象的引用,而这个模块对象表示的是a.mjs模块; - 然后,把
loaded属性的值修改成true。到了这里,我们就把b.mjs模块导出的这些属性所应具备的值,最终都确定了下来; - 现在执行另一个模块:
a.mjs,首先也是导出loaded,初始值是false; - 接着会让该模块所导出的
b得到初始值,这个值是一个指向b.mjs模块的引用; - 最后把
loaded属性的值设置为true,到了这里我们就把a.mjs模块导出的这些属性所对应的值确定了下来; - 这一步,系统就可以正式执行
main.mjs文件了,各模块所导出的属性全部已经求值完毕,由于系统是通过引用而不是复制来引入模块的,因此就算模块之间由循环依赖关系,每个模块也还是能够完整地看到对方地最终状态。
- �从
ESM与CommonJS交互使用技巧
CommonJS提供的一些关键引用,不受ESM支持,这包括:
requireexportsmodule.exports__filename__diranme
如果你试图在ES模块�中使用这些,那么由于这种模块运行与严格模式下,因为会让程序发生ReferenceError(引用错误)。
可以用下面的办法使用__filename和__dirname:
import { fileURLToPath } from 'node:url';
import { dirname } from 'node:path';
const __filename = fileURLToPath(import.meta.url);
const __dirname = dirname(__filename);
在ESM中,我们可以使用import.meta整个特殊的对象来获取一个引用,整个引用所指的是当前文件的URL。具体来说,就是通过import.meta.url这种写法,获取当前模块的文件路径,整个路径格式类似于“file://path/to/xxx.js”,然后使用fileURLToPath()把文件URL转成绝对路径。
CommonJS里的require()函数也可以使用下面这种写法,在ESM中使用require()加载CommonJS模块:
import { createRequire } from 'module';
const require = createRequire(import.meta.url);
// CommonJS 还可以引入 json 文件,但 ESM 还不行
const data = require('./data.json');
除了使用createRequire()这个方法加载CommonJS模块外,其实还可以用标准的import语法引入CommonJS模块,不过这种引入方式只能把默认导出的东西引进来:
import package from 'commonjs.js'; // 可行
import { method } from 'commonjs.js'; // 这样写会出错
我们没有办法在CommonJS模块里引入ES模块。
在ES模块的全局作用域中,this是未定义的(undefined),但在CommonJS模块系统中,它则指向exports引用:
// ESM
console.log(this); // undefined
// CommonJS
console.log(this === exports); // true